Welcome to CrowdGame
For full papar visit Cost-Effective Data Annotation using Game-Based Crowdsourcing.
Introduction
Usually, we know that we can annotate multiple tuples with labeling rules. For example, in entity matching, i.e., identifying whether any pair of product records is the same entity, as follows, we can find some textual rules to help us match records.
| Record a: Sony VAIO Silver Desktop Laptop |
| Record b: Apple Pro Black Desktop Notobook |
| Record c: Apple MacBook Pro Silver Laptop |
As shown in the example above, we can say that a product containing "Sony" is different from the one with "Apple". But the rules (Black, Silver) and (Laptop,Notebook) will lead to errors. This shows that labeling rules can help us labeling multiple tuples, but they also bring loss of labeling quality.
This paper introduces a cost-effective annotation approach, and focuses on the labeling rule generation problem that aims to generate high-quality rules to largely reduce the labeling cost while preserving quality.
To address the problem, we first generate candidate rules, and then devise a game-based crowdsourcing approach CrowdGame to select high-quality rules by considering coverage and precision. CrowdGame employs two groups of crowd workers: one group answers rule validation tasks (whether a rule is valid) to play a role of rule generator, while the other group answers tuple checking tasks (whether the annotated label of a data tuple is correct) to play a role of rule refuter. The two-pronged crowdsourcing task scheme is shown as follow.

We let the two groups play a two-player game: rule generator identifies high-quality rules with large coverage and precision, while rule refuter tries to refute its opponent rule generator by checking some tuples that provide enough evidence to reject rules covering the tuples. We iteratively call rule generator and rule refuter until crowdsourcing budget is used up.
Framework
We introduce a cost-effective data annotation framework as shown in figure below. The framework makes use of the labeling rules (or rules for simplicity), each of which can be used to annotate multiple tuples, to reduce the cost.
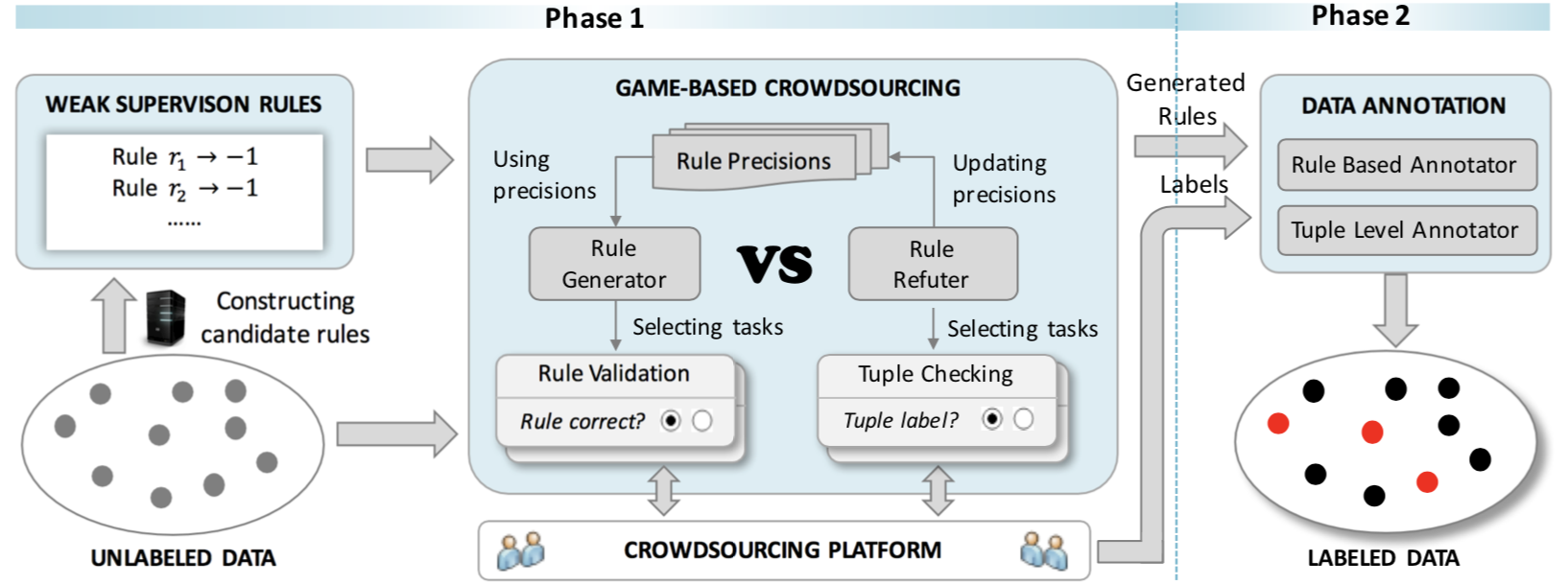
Our framework takes a set of unlabeled tuples as input and annotates them utilizing labeling rules in two phases.
-
Phase I: Crowdsourced Rule Generation. This phase aims at generating “high-quality” rules, where rule quality is measured by not only coverage but also precision. To this end, we first construct candidate rules, which may have various coverage and precision. Then we leverage the crowd on identifying good rules from noisy candidates.
-
Phase II: Data Annotation using Rules. This phase is to annotate the tuples using the labeling rules generated in the previous phase.
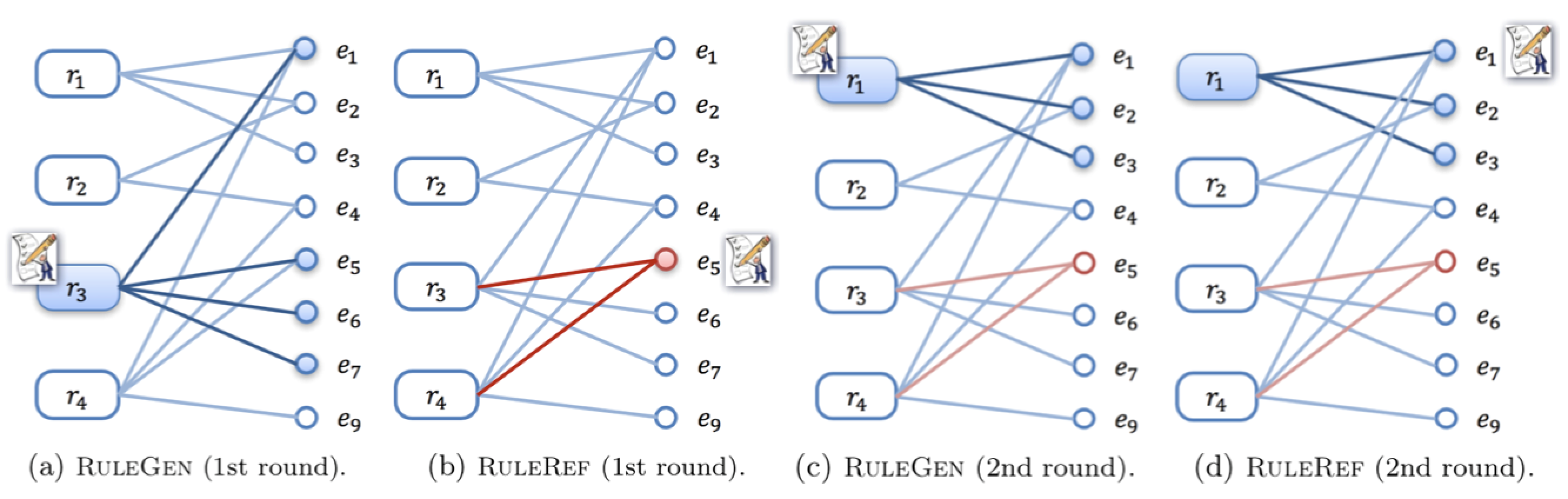
Let us use an example above to show how CrowdGame works, which is like a round-based board game between two players.
- In the first round, RuleGen selects r3 for rule validation, as it covers 4 tuples. However, its opponent RuleRef finds a “counter-example” e5 using a tuple checking task. Based on this, RuleRef refutes both r3 and r4 and rejects their covered tuples.
- In the second round, RuleGen selects another crowd-validated rule r1, while RuleRef crowdsources e1, finds e1 is correctly labeled, and finds no “evidence” to refute r1. As the budget is used up, we find a rule set R = {r1}.
We studies the challenges in CrowdGame. The first is to balance the trade-off between coverage and precision. We define the loss of a rule by considering the two factors. The second is to estimate accurate rule precision. We utilize Bayesian estimation to combine both rule validation and tuple checking tasks. The third is to select crowdsourcing tasks to fulfill the game-based framework for minimizing the loss.We introduce a minimax strategy and develop efficient task seselection algorithms.
For more details, please view our full paper.
Publication
- Jingru Yang, Ju Fan, Zhewei Wei, Guoliang Li, Tongyu Liu, Xiaoyong Du. Cost-Effective Data Annotation using Game-Based Crowdsourcing. PVLDB, 12 (1): 57-70, 2018.
- Ju Fan, Guoliang Li. Human-in-the-loop Rule Learning for Data Integration. IEEE Data Eng. Bull. 41(2): 104-115 (2018)
Datasets
We provide the 4 datasets used in our paper, including the tuple labels and the rule labels we got from AMT.
| Datasets | Descriptions | # Tuples to be annotated | # Candidate labeling rules | Download |
|---|---|---|---|---|
| Abt-Buy | Electronics product records from two websites, Abt and BestBuy. |
1.2 million | 1.6 w | Abt-Buy |
| Ama-Goo | Software products from two websites, Amazon and Google. |
4.4 million | 1.5 w | Ama-Goo |
| Ebay | Beauty products collected from website Ebay | 0.5 million | 1.3 w | Ebay |
| Spouse | Identify if two person in a sentence have spouse relation. |
5.5 k | 360 | Spouse |
Source Code
You can download the source code from Here. With Python3.5 installed, you can run this code with an example data set.
cd src
python run.py